


Vibes & Let All Go
Experiment 2: Phones over wearables, privacy wins, bye bye deep learning.


Timeline
July 2018 — August 2019
But Why?
The Goosecam taught us that rather than relying on wearables we need to detect context from the sensors available on smartphones.
Moreover, to be able to build a system that allows people to let all go, we need to recreate the friend that can sense our context (how we are feeling, where we are at, who else are we with etc.) very intuitively, and react to our implicit feedback (tapping of fingers, singing along etc.) in real-time. Therefore, in addition to the the phone sensors to accomplish the context part, we also need a very reactive reinforcement learning system to mimic the feedback part.
Experiment
Smartphone sensors for location, and motion combined with time can already give us a lot of context about a user. To detect emotions we had to tap into the microphone, and camera as well. By understanding the tone or facial expression of the users when they open the app, we could try to make sense of how they are feeling.
Although this combination of sensors sounded very promising it was a huge privacy invasion. As users we ourselves would not be comfortable giving such explicit biometric data to a company, and comfort is paramount if you want to let all go. This forced us to think of alternatives where users themselves would tell us their context, and the first version of Vibes (called Contexts back then) was created.
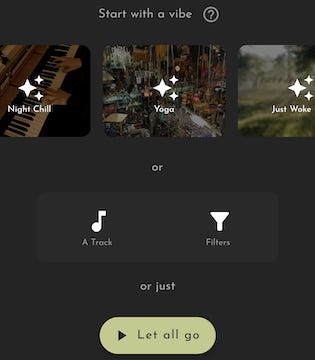
Users can create a vibe for an activity, a genre, an artist, or whatever their trigger for listening to music is. As they keep listening to music in that vibe their experience starts getting more and more personalised, and eventually leads to an experience where they just have to open the app, tap on ‘working’ and their working music automatically starts playing. It’s important to note that a vibe is not a static playlist, each recommendation is based on how you interacted with the previous track, and is calculated real-time.
To build such a reactive algorithm is a major challenge. Deep learning methods require a lot of data before they can give meaningful recommendations, and for them to react to reinforcement signals increases this sample complexity even further. After trying several approaches and failing, we eventually decided to create our own heuristic reinforcement learning algorithms; bye bye deep learning. Moreover, we built an interface suited to give the required feedback: users could left swipe to dislike, right swipe to skip, and love to show that they really like a track. These combined with our heuristic algorithms allowed us to recreate the feedback part of our friend.
To fully recreate our friend, we also needed to address the scenario in which we just want some music to play, but have no idea what to listen to. ‘Let All Go’ mode was created to solve this problem. A user just has to tap a button, and based on their past listening history we’ll recommend music to them. This is very similar to how a Youtube feed works.
Observations
Users absolutely loved the reactiveness of the new algorithm, and the left right swipe interface.
Vibes worked just fine for music recommendations. As users themselves were telling us their context, there was almost no noise and the quality of recommendations was way higher.
Majority of the users found it extremely hard to differentiate vibes from playlists, and could not understand the no list/feed approach to recommendations. Moreover, they generally think of music in terms of genres/artists, not vibes.
Let All Go was used far more than Vibes, and became the key draw to Lishash.
Music discovery was the main trigger for people to use let all go. For listening to music they already love, they still used playlists on their streaming service.
As we did not show any lists/feeds and people loved the discovery aspect of the app, they started asking for a lot more control (eg. playing only rock music).
Conclusion
Moving to smartphones from wearables worked perfectly; personalising let all go just based on time and recent history produced really good recommendations, and vibes improved the quality even further.
Designing heuristic algorithms in house is the way to go; deep reinforcement learning has too high a sample complexity to be useful.
Users will always use let all go more as its a single tap, and even though vibes are extremely useful they are too foreign a concept to understand.